
1. 패키지 설치 및 작업 경로 설정
# Package Installation
!pip install nltk
!pip install --upgrade pip
!pip install konlpy
!pip install wordcloud
!pip install --upgrade gensim
!pip install matplotlib
import pandas as pd
from konlpy.tag import Kkma
kkma = Kkma()
import nltk
from nltk import FreqDist
from konlpy.tag import Okt; t = Okt()
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
from wordcloud import WordCloud, STOPWORDS
# Specify the working directory
file_path = 'D:/*/'
2. 데이터 불러오기 및 전처리
# Read Excel data
data_hs = pd.read_excel(file_path + '*.xlsx', sheet_name=0)
# 제목 + 키워드 + 초록 합치기
df_hs = pd.DataFrame() # Create an empty dataframe
df_hs['year'] = data_hs['연도'] # Get the year
df_hs['words'] = data_hs['제목'] + ' ' + data_hs['키워드'] + ' ' + data_hs['초록']
df_hs['words'] = df_hs['words'].str.replace('\n', ' ') # 엔터링을 띄어쓰기로 대체
3. 형태소 분석
# 워드 클라우드 생성을 위해 모든 문자열을 하나로 합치기
combined_text = ' '.join(df_hs['words'].astype(str))
tokens_ko = t.nouns(combined_text) # 명사 분석
ko = nltk.Text(tokens_ko, name = 'keyword analysis')
print(len(ko.tokens)) # 토큰(문서 길이)의 수
print(len(set(ko.tokens))) # 고유 토큰의 수
ko.vocab() # Print words and their frequencies # 단어 및 빈도 출력
4. 빈도 분석
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
# 단어 빈도 그래프 생성
plt.figure(figsize=(12,6))
ko.plot(50) # Print most frequent 50 words
plt.show()
# 단어 및 빈도 csv 파일 생성
freq_dist = FreqDist(ko.tokens)
df_freq_dist = pd.DataFrame(freq_dist.items(), columns=['단어', '빈도']).sort_values(by='빈도', ascending=False)
df_freq_dist.to_csv(file_path + 'word_frequency.csv', index=False, encoding='cp949')
# 제외할 단어 설정
stop_words = ['것', '수', '및', '위', '등', '이', '비', '의', '그']
ko = [each_word for each_word in ko if each_word not in stop_words]
# 단어 빈도 그래프 재생성
ko = nltk.Text(ko, name='keyword analysis')
plt.figure(figsize=(12,6))
ko.plot(50)
plt.show()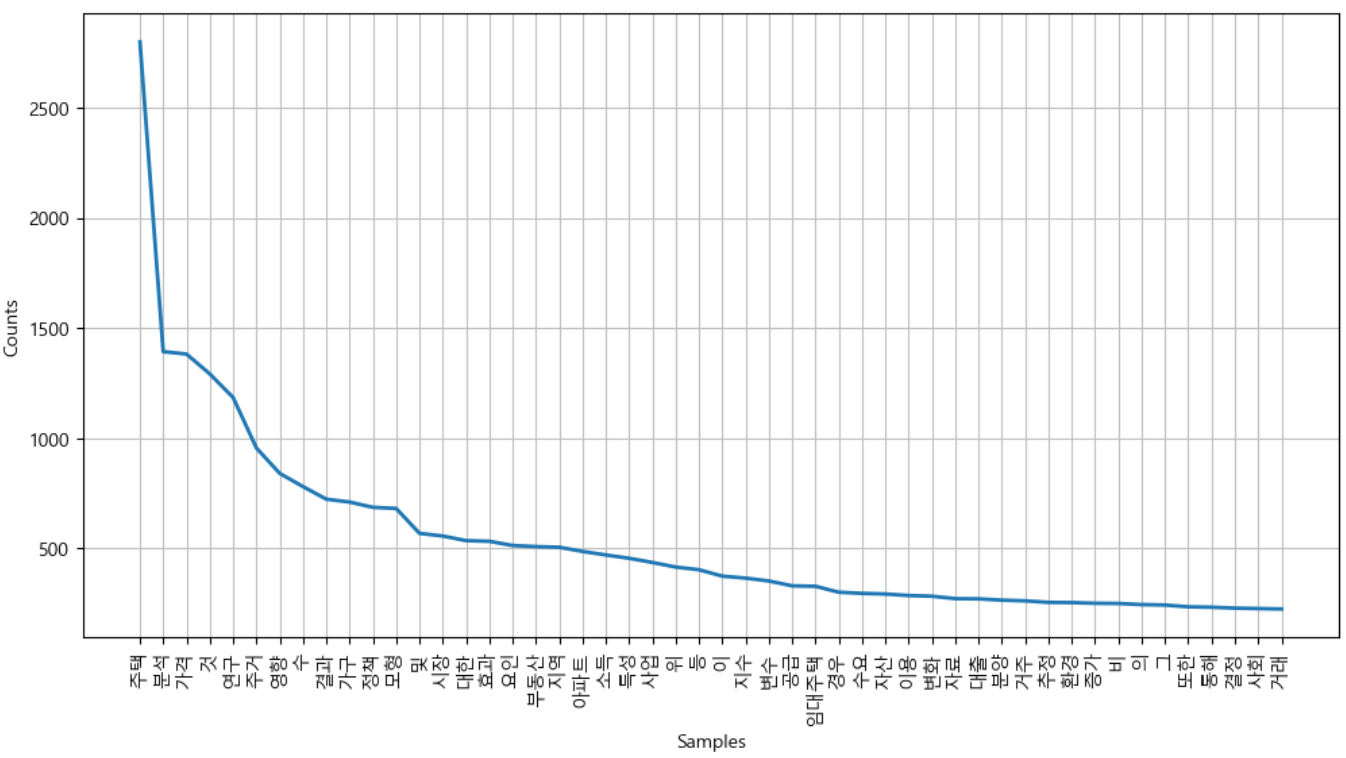

5. 워드 클라우드 생성
# 워드 클라우드 생성
data = ko.vocab().most_common(150)
wordcloud = WordCloud(font_path='c:/Windows/Fonts/malgun.ttf',
relative_scaling = 0.2,
background_color='white',
).generate_from_frequencies(dict(data))
plt.figure(figsize=(12,8))
plt.imshow(wordcloud)
plt.axis("off")
plt.savefig(file_path + 'wordCloud.png')
plt.show()필요에 따라 plt.savefig(*) 코드 생략 가능하며, plt.savefig()가 plt.show()보다 뒷 줄에 있을 경우 백지로 출력됨을 주의해야 한다.
plt 코드들은 plt 코드들끼리 한꺼번에 실행한다.


6. 원하는 모양으로 워드 클라우드 만들기
import numpy as np
from PIL import Image
mask = np.array(Image.open(file_path + 'cloud.png'))
data = ko.vocab().most_common(150)
wordcloud = WordCloud(font_path='c:/Windows/Fonts/malgun.ttf',
relative_scaling=0.2, mask=mask,
background_color='white',
).generate_from_frequencies(dict(data))
default_colors = wordcloud.to_array()
plt.figure(figsize=(6,6))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()

728x90
반응형
'Data Analysis > Python' 카테고리의 다른 글
| [Python] 키워드 분석 꼬꼬마 모듈 사용 중 java.lang.NullPointerException: java.lang.NullPointerException 오류 해결 (0) | 2024.02.19 |
|---|---|
| [Python] Window 10에 konlpy 설치하는 방법 (0) | 2024.02.07 |
| [Python] 한글 자연어 처리하기, Kkma, konlpy, 문장 분석, 단어 분석, 형태소 분석 (1) | 2024.02.06 |
| [API] 제주데이터허브 API key로 데이터 받는 법 (0) | 2023.10.25 |
| [Python] geocoding하는 법, 주소로 좌표 찾기 (0) | 2023.10.01 |



