토픽 모델링
토픽 모델링은 많은 양의 텍스트 데이터를 분석하는 데에 널리 사용되며, 토픽모델링 내에는 LSI(Latent Semantic Indexing), pLSI(probabilistic Latent Semantic Indexing), LDA(Latent Dirichlet Allocation) 등 다양한 기법들이 존재한다. 이 중 LDA는 문서 말뭉치(corpus)에서 잠재적인 토픽을 형성시키는 데에 가장 많이 사용되는 방법 중 하나이다.
토픽 모델링에서 문서 안의 단어들은 벡터로 표현되고, 이 벡터들을 조합하여 문서의 잠재적인 토픽을 형성한다. (수식 참고)
토픽 모델링에서는 문서 말뭉치가 잠재적으로 갖는 토픽의 개수를 설정하는 것이 중요하다. 이때 일관성(Coherence) 값을 이용할 수 있으며, 토픽 모델링으로 만든 토픽들의 상위 단어들이 높은 유사도를 가질수록 높은 일관성 값이 계산된다. 토픽 모델링은 확률적 생성 알고리즘을 기반으로 하므로 모델을 만들 때마다 그 결괏값이 조금씩 다르게 나타나는데, 이러한 확률적 변동성 문제 해결을 위해 일관성을 최대화하는 모델을 선택하는 것이 바람직하다.
토픽 수를 설정하여 LDA 모델을 만든 후에는 IDM(Intertopic Distance Map)을 작성하여, 추출된 토픽들의 비중과 유사도를 파악할 수 있다. 추출이 잘 된 토픽의 경우 원의 크기가 크고, 토픽들이 사분면 전체에 고르게 배치된다.
파이썬 코드
0. 단어 분석
토픽모델링 실행 전, 단어 분석이 선행되어 있어야 한다. 이 과정은 아래 글을 참고하면 되며 3번 과정까지 수행하면 된다.
https://luckylucy.tistory.com/133
[Python] 키워드 네트워크 분석 - 명사 분석, 동시 출현 빈도 분석, 키워드 네트워크 그래프 생성
1. 패키지 불러오기 # 패키지 설치 !pip install nltk !pip install --upgrade pip !pip install konlpy !pip install wordcloud !pip install --upgrade gensim !pip install matplotlib import pandas as pd import re from itertools import combinations from
luckylucy.tistory.com
1. 패키지 임포팅
import pandas as pd
from gensim import corpora # 단어 사전 생성 함수
from gensim.models import LdaModel # 토픽모델링 LDA 함수 생성
from pprint import pprint # 데이터 구조를 예쁘게 출력하는 모듈
import pyLDAvis.gensim_models as gensimvis
import pyLDAvis
from gensim.models import CoherenceModel # 일관성 분석
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc # 그래프에서 한글 폰트
2. 딕셔너리 생성
# 모든 키워드를 포함하는 딕셔너리 생성
dictionary = corpora.Dictionary(all_keywords)
# 문서-단어 행렬 생성
corpus = [dictionary.doc2bow(keyword) for keyword in all_keywords] # doc2bow: 각 단어를 수치화하고, 해당 문서 안에서 몇 번 나왔는지 카운트
3. 토픽 개수 선정을 위한 일관성 분석
# coherence 값을 저장할 리스트 생성
coherence_values = []
# 토픽 수 범위 지정
start_topic_count = 2
end_topic_count = 10
# 각 토픽 수에 대해 모델 학습 및 coherence 값 계산
for num_topics in range(start_topic_count, end_topic_count + 1):
lda_model = LdaModel(corpus=corpus, id2word=dictionary, num_topics=num_topics, passes=10) # passes: 모델을 학습시키는 횟수
coherence_model = CoherenceModel(model=lda_model, texts=all_keywords, dictionary=dictionary, coherence='c_v')
coherence_values.append(coherence_model.get_coherence())
# coherence 값이 가장 높은 토픽의 개수
num_topic = coherence_values.index(max(coherence_values)) + start_topic_count
# 한글 폰트 경로 설정 및 한글 폰트 설정
font_path = 'c:/Windows/Fonts/malgun.ttf'
font_name = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font_name)
# 그래프 그리기
plt.plot(range(start_topic_count, end_topic_count + 1), coherence_values)
plt.xlabel("토픽 수")
plt.ylabel("Coherence 값")
plt.title("Coherence 값의 토픽 수에 대한 변화")
plt.show()이때, 토픽의 수는 실행할 때마다 계속 변한다.

4. LDA 모델 및 IDM 생성
# LDA 모델 생성 (num_toics 파라미터에서 토픽 수 지정 가능 - 현재는 위에서 계산한 일관성을 최대로 갖는 토픽의 수(num_topic)를 가져옴)
lda_model = LdaModel(corpus=corpus, id2word=dictionary, num_topics=num_topic, passes=10)
# 토픽 및 해당 단어들 출력
pprint(lda_model.print_topics())
# 토픽 모델링 결과를 시각화
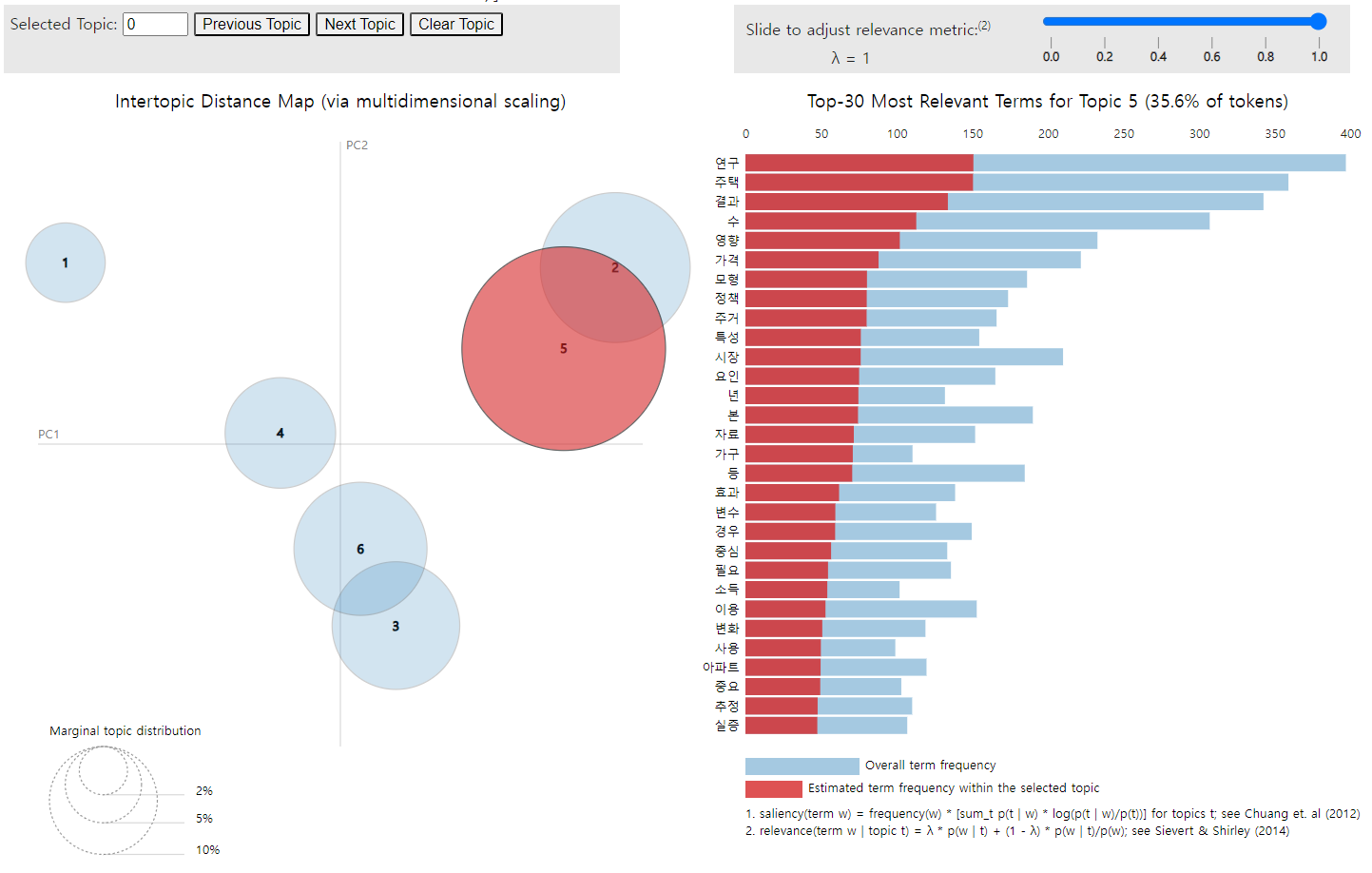
lda_display = gensimvis.prepare(lda_model, corpus, dictionary, sort_topics=False)
pyLDAvis.display(lda_display)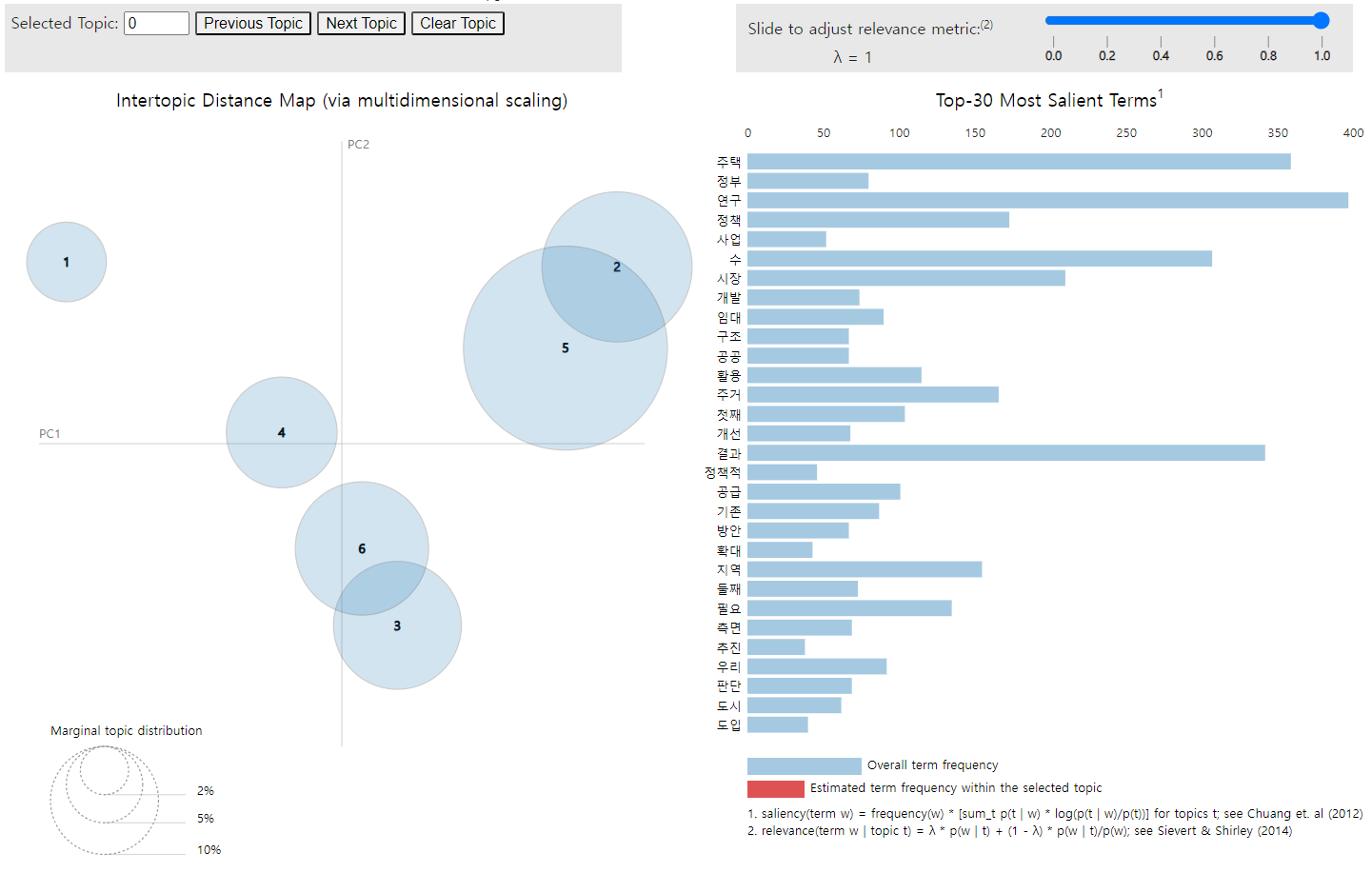
5. 각 토픽에 어떤 논문이 들어있는지 확인
# 모든 문서에 대한 주제 할당
document_topics = [lda_model.get_document_topics(doc) for doc in corpus]
# 문서별로 가장 높은 확률을 가진 주제 선택
dominant_topics = [(doc_id, max(topic, key=lambda x: x[1])[0]) for doc_id, topic in enumerate(document_topics)]
# 각 토픽에 속하는 문서 출력
topic_documents = {}
for doc_id, topic in dominant_topics:
if topic not in topic_documents:
topic_documents[topic] = []
topic_documents[topic].append(doc_id)
# 각 토픽에 속하는 문서 출력
for topic, documents in topic_documents.items():
print(f"토픽 {topic}에 속하는 논문:")
for doc_id in documents:
print(f"- 논문 {doc_id}")
# 주어진 정보로 DataFrame 생성
rows = []
for topic, documents in topic_documents.items():
for doc_id in documents:
rows.append({'토픽': topic, '논문': doc_id})
topic_documents_df = pd.DataFrame(rows)
# CSV 파일로 저장
topic_documents_df.to_csv('topic_documents.csv', index=False, encoding='utf-8-sig')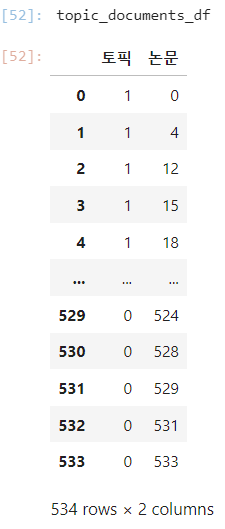
'Data Analysis > Python' 카테고리의 다른 글
| [Python] kakao map api를 활용한 지오코딩(geocoding) geokakao (0) | 2024.06.24 |
|---|---|
| [Python] geopandas 설치 오류 해결 (0) | 2024.06.23 |
| [Python] 키워드 네트워크 분석 - 명사 분석, 동시 출현 빈도 분석, 키워드 네트워크 그래프 생성 (2) | 2024.02.19 |
| [Python] 키워드 분석 꼬꼬마 모듈 사용 중 java.lang.NullPointerException: java.lang.NullPointerException 오류 해결 (0) | 2024.02.19 |
| [Python] Window 10에 konlpy 설치하는 방법 (0) | 2024.02.07 |



