<통계학 : 파이썬을 이용한 분석> 책 내용 중 '8장. 정규분포' 부분을 요약하였고, 필요한 내용은 더 추가한 글임을 미리 밝힙니다.
8. 정규분포(normal distribution)
8.2 연속확률분포
- 각 $x$값에 확률을 대응시키는 대신, 주어진 구간에서 확률이 어떻게 분포하는가 계산할 때 사용
- 확률밀도함수(probability density function)를 적용하기 위해서 다음을 만족해야 함
- (1) 모든 $x$값에 대해 $f(x)\geq 0$
- (2) $P(a\leq X\leq b)=\int_{a}^b{f(x)dx}$
- (3) $P(-\infty<X<\infty)=\int_{-\infty}^\infty{f(x)dx}=1$
8.3 정규분포의 일반적인 성질 및 확률계산
- 확률변수 $X$가 평균 $\mu$, 분산 $σ^2$을 갖는 정규분포를 따를 때, $X$의 확률밀도함수표준

- $\mu$는 분포의 중심을 나타내는 위치모수, $σ^2$는 평균으로부터 퍼져 있는 정도를 나타내는 모수가 됨
- 표준정규분포(standard normal distribution)
- 정규분포 중에서 평균이 0이고 분산이 1인 경우
- 확률변수 $Z$가 $N$(0, 1)이라고 할 때 $Z$는 0을 중심으로 대칭인 분포를 가짐
- $P[Z\leq-z]=1-P[Z\leq z]$
- 표준정규확률변수(standard normal random variable)
- 확률변수 $X$가 $N(\mu, σ^2)$일 때, 표준화된 확률변수 $Z=\frac{X-\mu}{σ}$는 평균이 0이고 분산이 1인 정규분포 $N$(0, 1)을 따름
8.4 이항분포의 정규분포근사
- 이항분포의 $np$와 $n(1-p)$가 모두 클 때 그 분포가 정규분포에 가까워짐
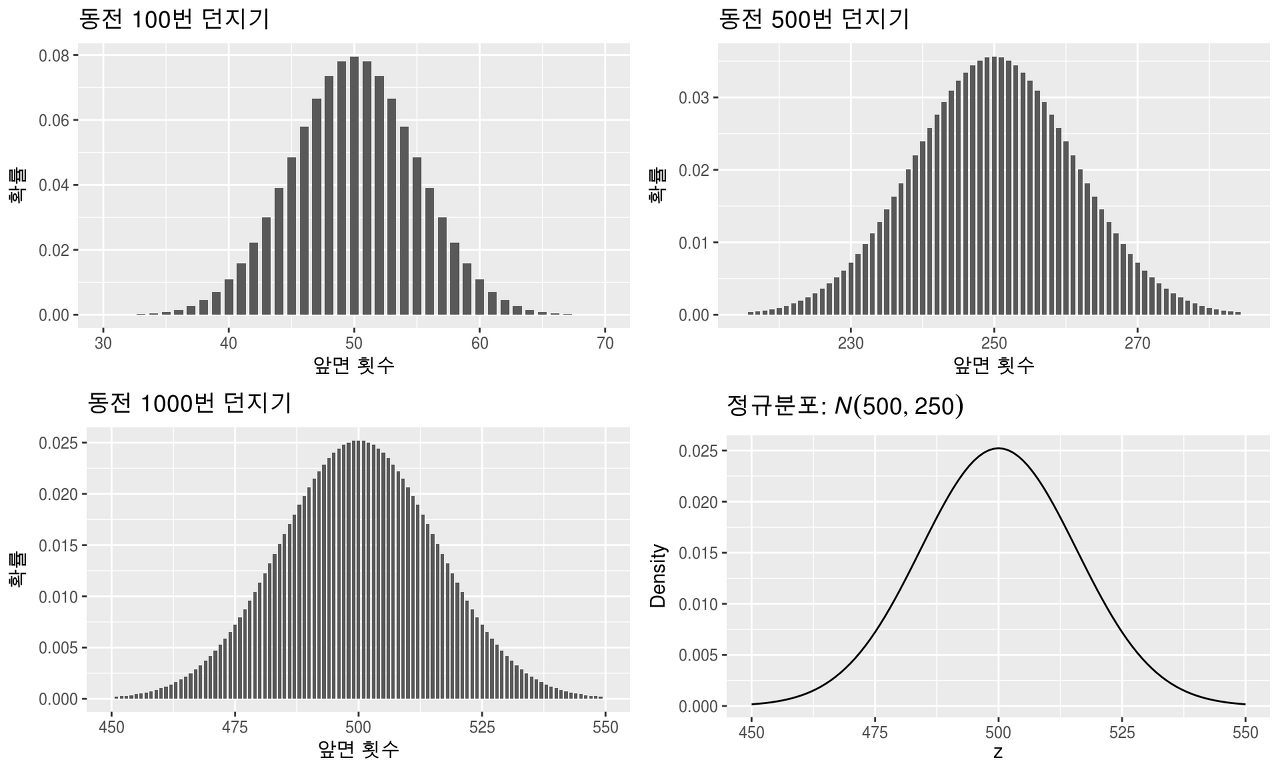
- 확률변수 $X$가 이항분포, 즉 $X$~$Bin(n,p)$이고 $np$나 $n(1-p)$가 모두 클 경우에(보통 10 이상) $X$는 근사적으로 평균이 $np$이고 표준편차가 $\sqrt {np(1-p)}$인 정규분포를 따름
- $Z=\frac{X-np}{\sqrt{np(1-p)}}$~$N(0,1)$로 표현
8.5 정규분포가정의 조사
- 많은 통계적 절차 및 분석의 경우 모집단이 정규분포를 따른다고 가정하고 있으나, 만약 정규분포가 아니라면 그 이후의 분석은 무의미해짐
- 표본을 추출했을 때 모집단이 정규분포인지 확인하는 방법
- 가장 쉬운 방법은 그래프 이용
- e) 히스토그램, 관측값과 정규분포의 확률밀도함수 비교
- 실제 자료가 $(\bar{x}-s, \bar{x}+s), (\bar{x}-2s, \bar{x}+2s), (\bar{x}-3s, \bar{x}+3s)$ 구간에 포함되는 비율과, 정규분포 특성상 통상적으로 포함되는 자료의 비율(68.3%, 95.5%, 99.7%)과 비교
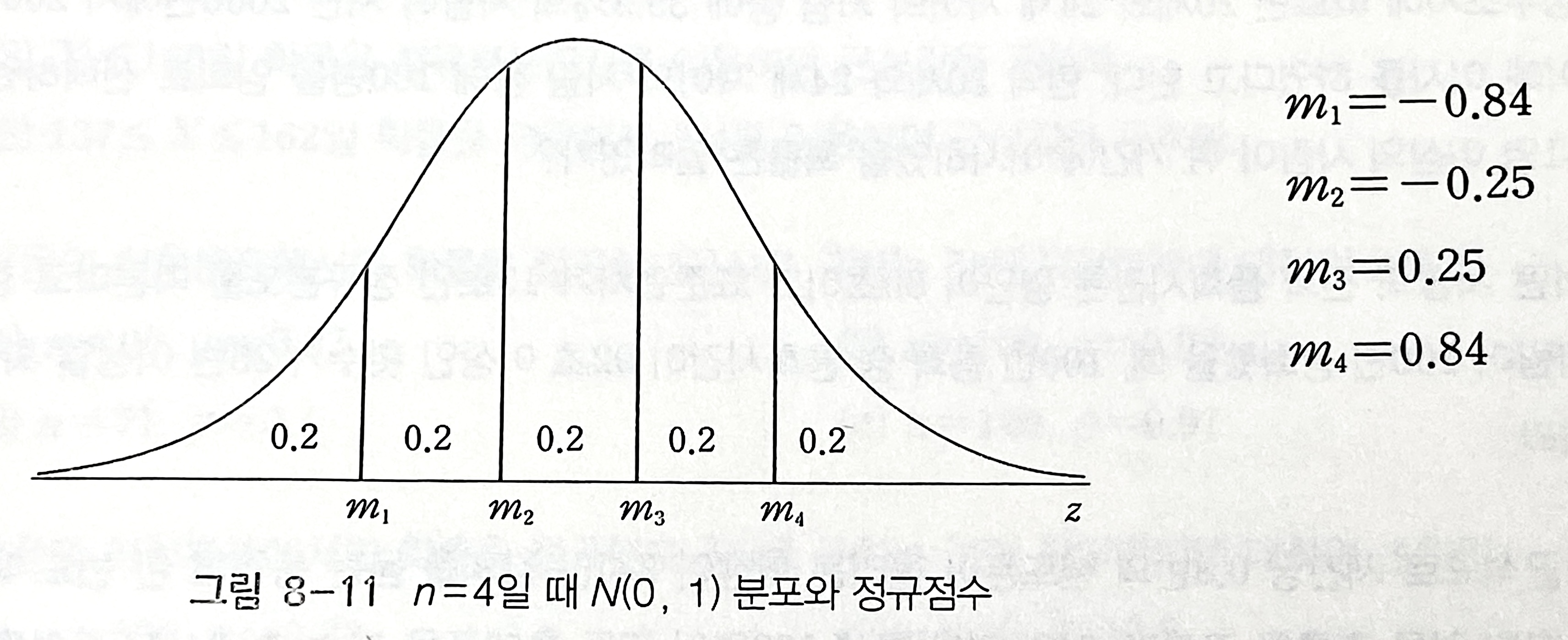
- 정규점수그림(normal scores plot) 또는 정규확률그림(normal probability plot)
- 정규점수(normal scores): 표준정규분포(평균 0, 표준편차 1)(정규분포를 표준화한 것)에서 이상적인 표본
- 즉, 표준정규분포의 확률밀도함수를 등확률 구간으로 나누어주는 경곗값(z값)을 의미
- e) 그림 8-11에서 4개의 지점($m_1, m_2, m_3, m_4$)은 확률밀도함수를 5개 등확률 영역(넓이)으로 나눈 것이며, 이 점들이 정규점수가 됨 (n분위수를 생각하면 쉬움)
- 정규분포표에서 0.2, 0.4, 0.6, 0.8 값과 가장 가까운 수를 찾으면, z 값은 -0.84, -0.25, 0.25, 0.84로 나옴
- 정규확률그림 그리는 법
- (1) 자료를 작은 것부터 크기순으로 나열
- (2) 각 자료에 해당하는 점수 계산
- (3) $i$번째 순서의 자료와 $i$번째 순서의 정규점수를 하나의 쌍으로 2차원 공간상에 표현
- 정규확률그림의 해석
- 이상적인 $x$값은 평균이 $\mu$고 분산이 $σ^2$인 정규모집단에서 등확률 간격으로 나누는 값이며, $x=\mu+σz$ 식을 통해 구할 수 있음
- 만약 모집단이 정규분포를 따른다면 관측된 x값과 정규점수($m_i$) 간에 직선 관계식이 성립함
- 자료의 변환
- 표본 크기가 작은 경우, 여러 통계분석을 하려면 모집단이 정규분포를 따른다는 가정 필요
- 추출된 표본이 정규확률그림 등에서 정규분포와 다르고 판명되면 자료 변환을 통해 정규분포 형태를 갖도록 시도할 수 있음(정해진 규칙은 없고 여러 가지 시도를 해봐야 함)
- 큰 자료값을 더 크게: $x^2, x^3$
- 큰 자료값을 작게: $x^{1/4}, \sqrt{x}, log \space x, 1/x$
- 저자
- 인하대학교 통계학과
- 출판
- 자유아카데미
- 출판일
- 2022.06.25
'GIS > Statistics' 카테고리의 다른 글
| [기초통계] 통계적 추론–표본의 크기가 클 때–(모평균의 추정, 모평균에 대한 검정, 모비율에 대한 추론) (1) | 2023.01.27 |
|---|---|
| [기초통계] 표집분포(계량의 확률분포, 표본평균의 분포와 중심극한정리) (0) | 2023.01.18 |
| [기초통계] 이항분포와 그에 관련된 분포들(베르누이 시행, 이항분포, 초기하분포, 포아송분포) (0) | 2023.01.16 |
| [기초통계] 확률분포(확률변수, 이산확률변수와 확률분포, 확률분포의 기댓값과 표준편차, 두 확률변수의 결합분포, 공분산과 상관계수, 두 확률변수) (0) | 2023.01.11 |
| [기초통계] 확률(사건의 확률, 확률의 계산, 확률법칙, 조건부확률과 독립성) (2) | 2023.01.10 |



